Architecture Pitfalls: Don’t use your ORM entities for everything — embrace the SQL!


When designing an application with JPA/Hibernate, I’ve encountered a common pattern that suggests developers should channel as many of their interactions as possible with their database via their persistence entities and ORM, avoiding writing SQL at all costs.
This mostly seems to stem from a belief that this approach will maximise model flexibility and database portability. Sometimes it's also an aversion to learning SQL.
There’s a grain of truth to the portability argument, but in practice, restricting yourself so significantly is usually a bad decision for a few reasons that I'll outline in this post.
Will you actually need to change between fundamentally different database technologies?
It can be helpful to survey a few business and technical aspects of the project to see what latitude you can grant yourself.
Validate whether you really need portability between SQL and NoSQL databases. If you assess that a relational data model is a good match for your requirements, it's quite unlikely you will change to a completely different model later on.
Usually, it is not worth spending too much effort trying to preserve the ability to switch to an alternative storage technology (unless you are absolutely certain you need it).
Decisions in this area may fall to your technical architects and product management. You should make them aware of the burdens they are imposing with requirements like this.
A much more common real-world requirement is portability between different SQL databases and versions — especially if you are an application vendor with multiple customers who might prefer to use different databases. More on this later.
As an aside, good architectural practices (such as the use of Hexagonal Architecture) will make it possible for you to refactor to a new storage technology in future without breaking public interfaces, which will almost certainly be a better approach than trying to achieve the Sisyphean task of completely abstracting implementation code from its underlying persistence technology.
Don’t run away from SQL, embrace it!
I suspect one of the greatest lies ever told in web application development is that if you use an ORM you can avoid writing and understanding SQL, “it’s just an implementation detail”. That might be true at first, but once you go beyond the basics that falls away quickly.
As an example, I quite commonly see the findAll plus filter antipattern. This is when you fetch all records from a collection and then use your application to perform some simple filtering to include/exclude records.
It’s much better to let the database do this kind of filtering. After all, it’s what all of the clever folk who work on databases spend a lot of time and effort optimising.
For most ORMs you have the option of writing analogues to SQL which can get you quite a long way. For example, JPA has JPQL and Hibernate has HQL. These let you build abstracted queries that should work on all databases that your ORM supports.
The implication of this is that your team needs to embrace SQL and understand how to use it, rather than avoiding it by using application code instead.
To dispel a common source of anxiety on this: you don’t need to be a SQL guru to get started and become familiar with what you will need for the vast majority of your implementation requirements. There are also excellent resources and books available, I will link some below.
Contrary to some hyperbolic claims in the past, SQL isn’t going anywhere and is not just a legacy technology. Basic SQL knowledge is a good investment in your career and you will find it useful all over the place.
Escaping the Native SQL trap
ORM SQL analogues like JPQL will only get you so far, once you start doing more complex stuff you will find that you are straying beyond what is possible (your mileage will vary on this, depending on which ORM and version you are using).
For example, if you want to create a materialised view, triggers, more complex query structures, etc, you usually won’t find this in your ORM.
There are broadly two reasonable solutions to this:
1) Write strictly standards-compliant native SQL. This can work reasonably well for simpler situations, but many databases are not fully SQL standard compliant, so you will get some unwelcome surprises that require refactoring to find the lowest common denominator.
2) Use a fluent SQL builder like jOOQ to handle the problem of “what SQL should I produce for this statement” on your behalf. This lets you write your query the way you prefer to write it, and jOOQ will figure out the right SQL statement for the database and version you are targeting. Equivalents exist for other languages.
As of today, I would say that the latter approach is better if you can go that direction — getting stuck maintaining native SQL can be a real hassle if you need to support multiple databases. If possible, let a library like jOOQ handle it for you!
Programmatic query building
This is Java-specific, but I strongly recommend avoiding the JPA Criteria API. By modern standards, the design of the criteria builder is byzantine, and people find it extremely difficult to comprehend and maintain the code.
Thankfully, there are now some great alternatives that won’t give you a headache. Again, two solutions that I can personally recommend are: jOOQ and BlazePersistence.
Both give you access to a modern, fluent API that lets you build queries programmatically without hassle.
BlazePersistence is Hibernate-centric, but is free for all databases, whereas jOOQ has a much broader set of functionality but requires a modest per-developer fee for certain non-free enterprise databases. I think jOOQ is worth paying for, but you may have to battle with your company’s beancounters to get approval. If you're using common free and open source databases like Postgres, jOOQ is free.
Projections are your friend
A pattern I commonly see is to always return full ORM entities in queries, and then copy only the fields needed to DTOs (which are then returned to the caller).
For simpler use-cases this is often fine, but it can have a significant performance impact for queries that are larger and/or more expensive. To put it another way, you are causing significant extra work in the database, serialisation, deserialisation and network traffic just to throw away most of the data. You’ll probably also notice that “real” ORM entities can have a fair bit of overhead associated with them; that's because key functionality that your ORM provides requires injection of proxies, interceptors, wrappers, etc.
Instead, you should consider using projections. In essence, this is simply a SQL query that returns only the data you need, with the results mapped into objects specifically designed to hold that data. This will often be flattened and simplified compared to your data model. The benefit is that it’s lightweight and removes unnecessary overhead. The downside is that these are typically not 'real' entities, so you can't do write operations with them — usually, you don't want to do that anyway!
As of writing, I find JPA/Hibernate’s inbuilt way of handling projections to be extremely inconvenient and difficult to maintain (e.g. verbose constructor-based syntax). I suspect this might be the reason so many people use the inefficient "application projection" way of doing things.
Instead, I recommend using BlazePersistence’s Entity View module or jOOQ’s DTOs/projections. These both provide much more convenient ways of mapping, often with code generation to remove the requirement to keep your Java class "in sync" with your projection query.
Experience says use of projections pays off very quickly when returning bulk data and complex queries, so don’t be shy!
Incidentally, if you are using a newer version of Java, you can also make use of records to further reduce boilerplate noise.
A potential caveat is that if you are using a second-level cache with your ORM, you may need to selectively flush it to avoid staleness issues. People have strong opinions on second level caches in ORMs, and I’m not going into that area here!
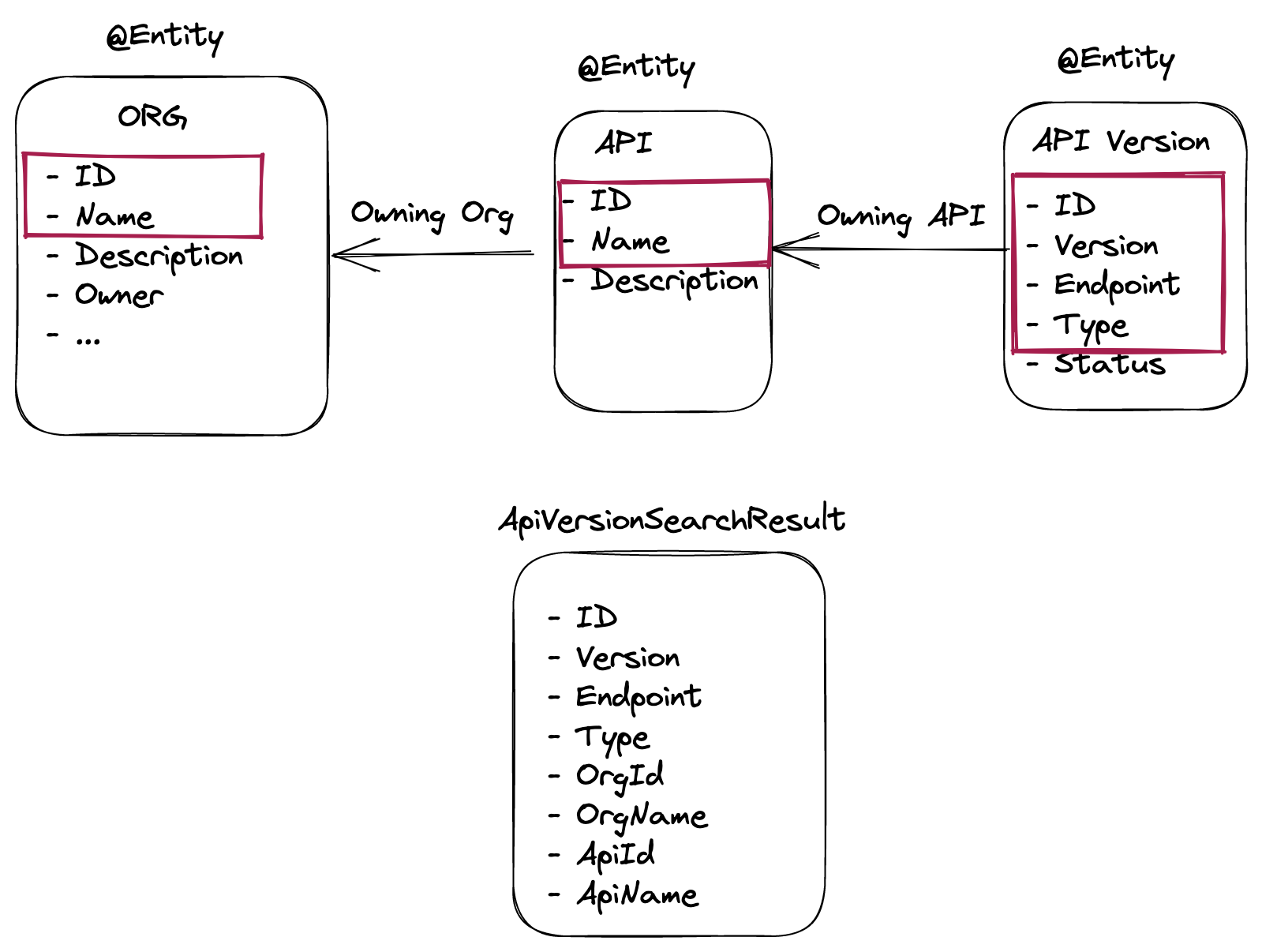
Let's run through a quick example.
Imagine you have a listing endpoint that returns an entity, which is in turn related to another couple of entities. You want to return only a subset of the total fields (highlighted in red). By using the projection ApiVersionSearchResult you get a simple and compact representation which you can change without changing the rest of your API. And your database will thank you for using a query that only selects the fields it needs.
In practice, to achieve this you would create a simple query and 'project' it into your ApiVersionSearchResult. The specifics of implementation vary depending on your chosen approach. Here are a few popular ones:
- jOOQ — DTO Projection (blog), Lukas Eder
- Spring Data — "The best way to fetch a Spring Data JPA DTO Projection", Vlad Mihalcea
- BlazePersistence — Entity Views, BlazeBit
As an aside, I've also seen systems that return "projections" using existing @entity objects with null fields and using Jackson's Include.NON_NULL, which means fields that are null don't appear in the serialised payload; a kind of poor man's projection. You are setting yourself up for problems in the future by doing this, so I recommend avoiding such patterns.
Don’t be afraid to mix and match
Use your ORM for basic functions (often a large proportion of what you need), and use alternatives when you stray beyond its capabilities. Don’t feel you need to buy in completely to a single approach.
But, this is all so obvious!
More experienced developers will often say this is all so obvious. Yet I’ve seen all of these mistakes numerous times, so evidently it bears repeating. As an industry, I suspect we’re not very good at passing down institutional knowledge on these subjects to younger developers.
Plus, in software engineering, we love throwing away orthodoxy until we discover that we did it the old way for a reason. For example, the “SQL is dead” fad that started in about 2012, followed by the SQL renaissance when we realised it's actually quite good at a lot of things (and incorporated some of the ideas of the NoSQL stores, such as JSON support).
Book Recommendations

Vlad is very well known in the Java and JPA community. His book is a great guide to all things JPA and Hibernate, with many patterns that are applicable across different ORM stacks. If you are having performance problems with your Hibernate/JPA application, High-Performance Java Persistence is very helpful.
HPJP is fairly broad in its purview, covering the fundamentals of relational databases, and how to design your application to be sympathetic to the underlying technologies. It's also a good reference when kicking off new projects, helping instil best practices in your engineering and architecture teams. It's much easier to establish beneficial design patterns early on, rather than piling up technical debt that's difficult to undo later.
There's a fair bit of jOOQ content here, too, so if you are wanting a book that can cover a bit of everything, then HPJP can be a good option.
